
The Truth About Secrets
Uncovering hidden themes in anonymous social media through Natural Language Processing
Nothing makes us so lonely as our secrets. – Paul Tournier
Secrets can take so many forms: from lighthearted to intense, regrettable to silly, and everything in between. I became interested in studying secrets because I feel you can learn a lot about society from the things that people are afraid to admit in public. By definition, you rarely get to peek behind the curtain, but people become surprisingly honest and vulnerable when you give them the benefit of anonymity. I collected the data for my analysis from Whisper, an anonymous social media platform for sharing secrets.

You can see what people tend to talk about from a high level in this word cloud, but let’s dig a little deeper.
Sentiment Analysis
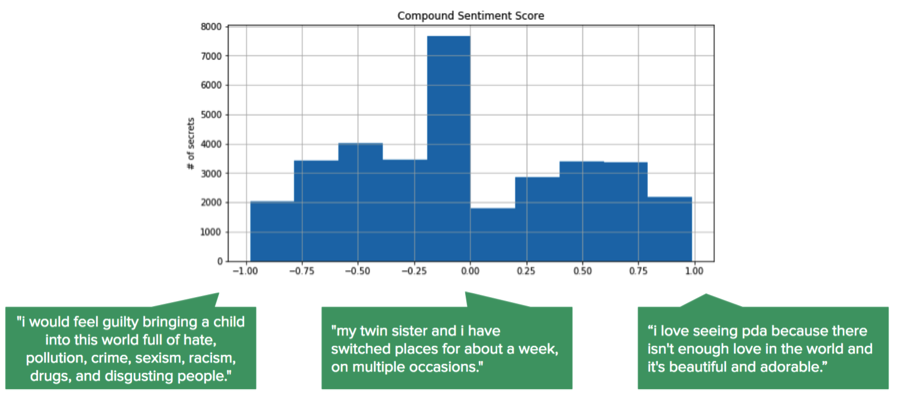
I used VADER Sentiment Analysis to get the sentiment scores for all secrets in my dataset. A higher score means the message is generally more positive, while a lower score means it is more negative.
I was surprised to find that the secrets were generally fairly balanced, with most falling on the neutral or slightly negative side. The image below shows the exact breakdown of the scores as well as some examples of messages within those groups.
Topic Modeling
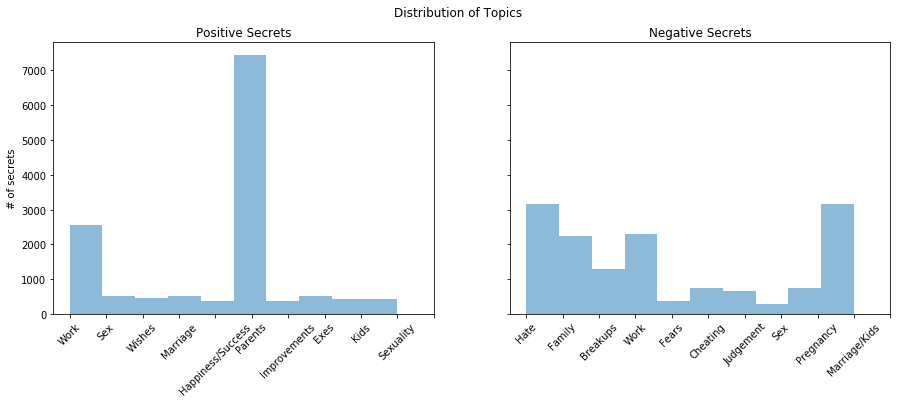
I extracted topics from the data using Non-negative Matrix Factorization (NMF). I summarized the top 10 topics across the entire dataset as follows:
- Parents/family
- Sex
- Jobs/Money
- Exes
- Hatred
- Marriage
- Kids
- Pregnancy
- High School/College
- Dating
I used the highest NMF coefficient for each secret to classify it into a topic and found that the topics for parents/family, jobs/money, and exes were by far the most common. However, many secrets had extremely low NMF coefficients (less than .00001) so I had to take this interpretation with a grain of salt. I experimented with my topics, expanding them beyond interpretability, and played with clustering models such as DBSCAN and K-means. I couldn’t seem to get any meaningful results for those noisy points. As I investigated them, I found that there were simply a lot of secrets along the lines of “It feels like a sin to wash bacon grease off a pan”.
Interestingly, I found a very different distribution of topics among positive and negative secrets from my sentiment analysis. Understandably, the positive secrets are people gushing about happy moments that they want to share. The people’s secrets with negative tones tend to be about marriage, work, and things they hate.
Web App Mockup
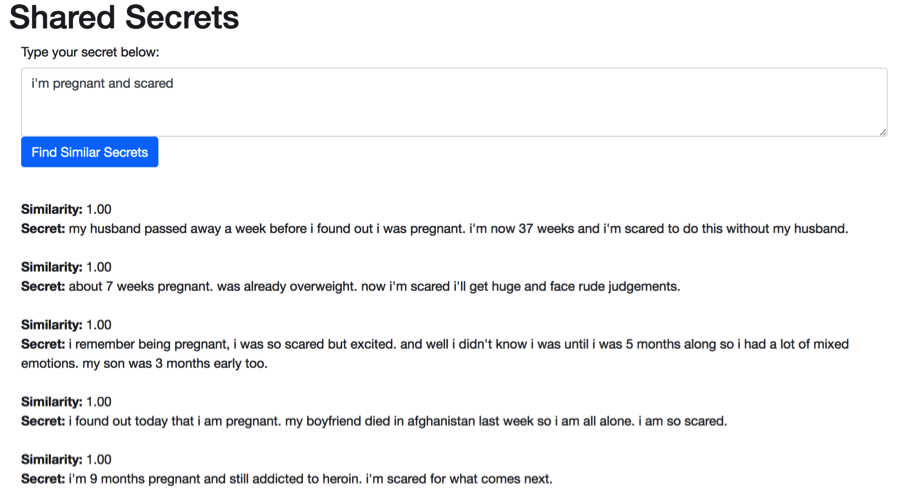
There is some comfort in knowing that you’re not alone when you are struggling with a heavy secret. I made a simple mockup of a site where users can type their secret and the model will pull up the most similar secrets by cosine similarity.
Conclusion
There is a lot to learn from secrets. I would like to continue to explore them from additional angles. Some other ideas I have include building a supervised learning model to classify the higher themes of secrets (such as insecurities or regrets). I would also like to study secrets of people from other countries to understand how taboos may vary by cultures. Finally, I think it would be fascinating to compare my findings from Whisper to a public social media site such as Instagram or Facebook. When you look at a word like “pregnancy”, for example, you’ll see that it carries a lot of baggage on an anonymous site like Whisper. However, it is a topic that many people discuss positively, or even boastfully, on Facebook.